8 minutes
Fuzzing Pillow with Frelatage to find bugs and vulnerabilities
🧐 What is fuzzing?
Fuzzing or fuzz testing is an effective way to find bigs or vulnerabilities in a software or a library. The program which is used to fuzz is called the fuzzer (for example: AFL, HongFuzz or wfuzz) and the program being fuzzed is our target. A fuzzer typically starts feeding the target program with random inputs while observing its behaviour. Whenever the target crashes, the fuzzer reports the input which caused the crash to the user as a bug or a crash.
This method has proven its value many times in vulnerabilities and bugs research, as shown in these different articles and videos:
- Fuzzing the linux kernel with AFL++
- Pulling JPEGs out of thin air (THE article that made me interested in fuzzing)
- Fuzzing Google V8 JavaScript Engine with Dharma
- Fuzzing A GameBoy Emulator With AFL++
So a few weeks ago, I immersed myself into this new world, and after spending a lot of time playing with AFL++, HongFuzz and Atheris on a lot of programs, I felt like writing my own fuzzer, first for learning purposes, then for finding vulnerabilities. A few nights of code later, Frelatage was born.
🏭 Frelatage
Frelatage is a coverage-based Python fuzzing library which can be used to fuzz python code.
-> It is a mutation-based fuzzer. Meaning, Frelatage generates new inputs by slightly modifying a seed input, using different method such as duplicating a part of the input, or modifying a segment of it.
-> Frelatage is also a greybox fuzzer (not blackbox nor whitebox). Meaning, Frelatage leverages coverage-feedback to learn how to reach deeper into the program. It is not entirely blackbox because Frelatage leverages at least some program analysis. It is not entirely whitebox either because Frelatage does not build on heavyweight program analysis or constraint solving. Instead, Frelatage uses lightweight program instrumentation to glean some information about the coverage of a generated input. If a generated input increases coverage, it is used afterwards for further fuzzing.
📕 Influences
The development of Frelatage was inspired by various other fuzzers, including AFL/AFL++, Atheris and PythonFuzz.The main purpose of the project is to take advantage of the best features of these fuzzers and gather them together into a new tool in order to efficiently fuzz python applications and libraries.
- 🕵️ How it works
- 👍 Setting up our fuzzing environment
- ✍️ Writing the fuzzing harness
- 🦘 Running the fuzzer
- 💥 Triaging the crashes reports
- 👉 Upcoming features
🕵️ How it works
The idea behind the design of Frelatage is the usage of a genetic algorithm to generate mutations that will cover as much code as possible (frelatage is a coverage-based fuzzer). The process of a fuzzing cycle can be roughly summarized with this diagram:
👍 Setting up our fuzzing environment
⚙️ Installing Frelatage
The package is available on PyPi and can be installed simply with pip:
pip3 install frelatage
🏗️ The project structure
# Create the main folder
mkdir pillow_fuzz
cd pillow_fuzz
# Create the input file folder
mkdir in
# Create the dictionary folder
mkdir dict
# Create the fuzzing harness file
touch pillow_fuzzer.py
Once these operations are done, we have a tree structure of this form:
├── pillow_fuzzer.py
│ ├── dict
│ ├── in
📝 Creation of a corpus
A corpus is a set of inputs for a fuzz target. In most contexts, it refers to a set of minimal test inputs that generate maximal code coverage.
Pillow being an image processing library, we will need a corpus of images to reach a satisfactory code coverage and help the fuzzer to find interesting paths. The official documentation of the library informs us that the following formats are fully supported:
- BMP
- DDS
- DIB
- EPS
- GIF
- ICNS
- ICO
- IM
- JPEG
- JPEG 2000
- MSP
- PCX
- PNG
- Saving
- PPM
- SGI
- SPIDER
- TGA
- TIFF
- WebP
- XBM
In order to optimize the efficiency of the fuzzer, it may be relevant to write a different fuzzing harness for each supported format. This includes the creation of a dictionary specific to each format, as well as a dedicated corpus for each fuzzing harness.
What we call a fuzzing harness is a test case or a particular test target.
For this article, we will focus on the JPEG format, on the one hand because it is one of the most widespread formats, and on the other hand because it is the format for which it is the easiest to find a corpus (with PNG and GIF).
There are already pre-made corpus freely available, for the needs of our work we will use this one
# Download the corpus
svn export https://github.com/strongcourage/fuzzing-corpus/trunk/jpg
# Merge all subfolders into the ./in folder
cp jpg/*/* ./in
rm -rf jpg
📙 Dictionary-based optimizations
A JPEG image consists of a sequence of segments, each beginning with a marker, each of which begins with a 0xFF byte, followed by a byte indicating what kind of marker it is.
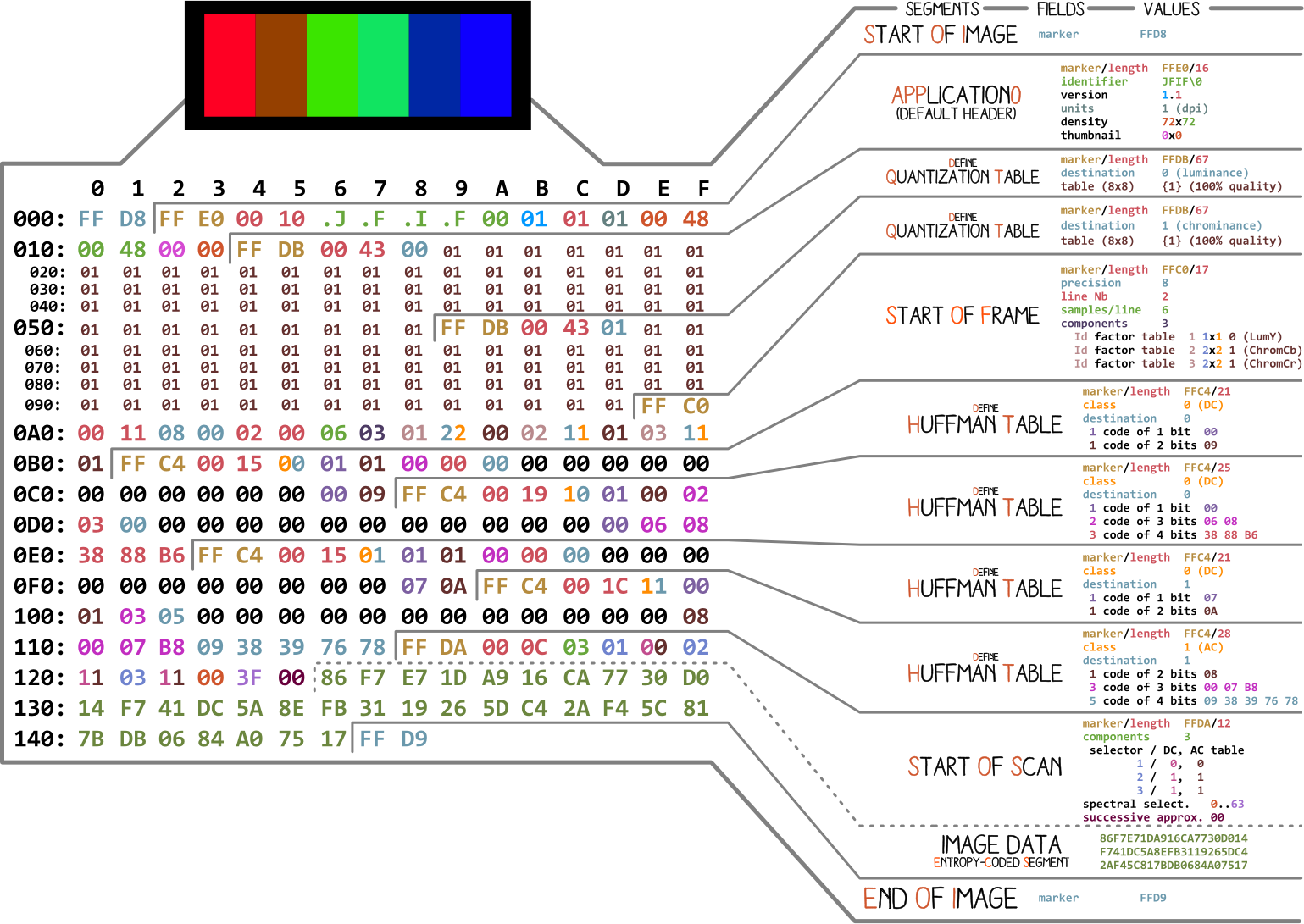 |
|---|
| representation of a JPEG file |
We will use this dictionary that was written for AFL by Michal Zalewski.
#
# AFL dictionary for JPEG images
# ------------------------------
#
# Created by Michal Zalewski
#
header_jfif="JFIF\x00"
header_jfxx="JFXX\x00"
section_ffc0="\xff\xc0"
section_ffc2="\xff\xc2"
section_ffc4="\xff\xc4"
section_ffd0="\xff\xd0"
section_ffd8="\xff\xd8"
section_ffd9="\xff\xd9"
section_ffda="\xff\xda"
section_ffdb="\xff\xdb"
section_ffdd="\xff\xdd"
section_ffe0="\xff\xe0"
section_ffe1="\xff\xe1"
section_fffe="\xff\xfe"
it will be saved in the ./dict folder (default folder for dictionaries)
✍️ Writing the fuzzing harness
Our fuzzing harness will be in pillow_fuzzer.py.
import frelatage
from PIL import Image
from PIL import ImageFile
# Allow PIL to load truncated images
ImageFile.LOAD_TRUNCATED_IMAGES = True
# The function we want to fuzz
def jpeg_fuzz_pillow(image):
# We fuzz the "open" method
Image.open(image)
return
# Load the corpus
jpeg_corpus = frelatage.load_corpus(directory="./")
# Initialize the fuzzer
f = frelatage.Fuzzer(jpeg_fuzz_pillow, [jpeg_corpus])
# Launch the fuzzing process
f.fuzz()
🦘 Running the fuzzer
I have developed frelatage to be highly configurable, so it is possible to change several constants through environment variables:
| ENV Variable | Description | Possible Values | Default Value |
|---|---|---|---|
| FRELATAGE_DICTIONARY_ENABLE | Enable the use of mutations based on dictionary elements | 1 to enable, 0 otherwise |
1 |
| FRELATAGE_TIMEOUT_DELAY | Delay in seconds after which a function will return a TimeoutError | 1 - 20 |
2 |
| FRELATAGE_INPUT_FILE_TMP_DIR | Temporary folder where input files are stored | absolute path to a folder, e.g. /tmp/custom_dir |
/tmp/frelatage |
| FRELATAGE_INPUT_MAX_LEN | Maximum size of an input variable in bytes | 4 - 1000000 |
4094 |
| FRELATAGE_MAX_THREADS | Maximum number of simultaneous threads | 8 - 50 |
8 |
| FRELATAGE_MAX_CYCLES_WITHOUT_NEW_PATHS | Number of cycles without new paths found after which we go to the next stage | 10 - 50000 |
5000 |
| FRELATAGE_INPUT_DIR | Directory containing the initial input files. It needs to be a relative path (to the path of the fuzzing file) | relative path to a folder, e.g. ./in |
./in |
| FRELATAGE_DICTIONARY_DIR | Default directory for dictionaries. It needs to be a relative path (to the path of the fuzzing file) | relative path to a folder, e.g. ./dict |
./dict |
So we start by configuring our fuzzer:
export FRELATAGE_DICTIONARY_ENABLE=1 &&
export FRELATAGE_TIMEOUT_DELAY=2 &&
export FRELATAGE_INPUT_FILE_TMP_DIR="/tmp/frelatage" &&
export FRELATAGE_INPUT_MAX_LEN=4096 &&
export FRELATAGE_MAX_THREADS=8 &&
export FRELATAGE_MAX_CYCLES_WITHOUT_NEW_PATHS=5000 &&
export FRELATAGE_INPUT_DIR="./in" &&
export FRELATAGE_DICTIONARY_DIR="./dict" &&
Then we launch it
python3 pillow_fuzzer.py
 |
|---|
The fuzzing process can take from a few hours to several days, depending on the new paths found by fuzzing during the process.
💥 Triaging the crashes reports
now enters the less pleasant part, namely triaging the crashes.
Crash triage involves examining each crash discovered by Frelatage to determine whether the crash might be worth investigating further (for security researchers, this typically means determining whether the crash is likely due to a vulnerability) and, if so, what the root cause of the crash is. Reviewing each crash in detail can be very time consuming, especially if the fuzzer has identified dozens or hundreds of crashes. This will probably be the case if you leave Frelatage running for several hours/days.
Each crash is saved in the output folder (./out by default), in a folder named : id:<crash ID>,err:<error type>,err_file:<error file>,err_pos:<err_pos> Which you can read as follows:
- id: The crash number, e.g. 000001
- err: The type of error triggered, e.g. OSError, AttributeError
- err_file: File in which an error has occurred, e.g: image
- err_pos: Line where an error occurred, e.g. 34
-> The report directory is in the following form and contains files passed as argument:
├── out
│ ├── id:<crash ID>,err:<error type>,err_file:<error file>,err_pos:<err_pos>
│ ├── input
│ ├── 0
│ ├── <inputfile1>
│ ├── ...
│ ├── ...
 |
|---|
| Examples of reports generated by Frelatage |
📄 Read a report
Inputs passed to a function are serialized using the pickle module before being saved in the <report_folder>/input file. It is therefore necessary to deserialize it to be able to read the contents of the file. This action can be performed with this script.
./read_report.py input
{'input': [{'value': '/tmp/frelatage/0/0/0e8ef3773a13824c42f021c1af856c351effa6a2-2', 'file': True}]}
👉 Upcoming features
Frelatage is still in active development, so what has been written above may (will?) change, as I plan to work on new features to make my fuzzer even more effective.
Here are the features I plan to implement in the next few weeks:
- Possibility to use different dictionaries for each input
- Implementation of a crash triage system
- A more colorful interface (who wants to work with dull tools?)
To keep up to date with the changes made to Frelatage, the very best way is to look at the Github repo
😃 Thanks for reading!
for more informations or suggestions, you can contact me at: r0g3r5@protonmail.com, or on twitter at @Rog3rSm1th